
 番外編
Chap.10 マルチタスクOS理解への第一歩/ラダー図でメモリをつくる(3)
番外編
Chap.10 マルチタスクOS理解への第一歩/ラダー図でメモリをつくる(3)お久しぶりです。
長らくお休みしていた番外編を再開いたします。
番外編の最後の更新は、2000年5月でした。
今は、2004年11月、いつのまにか21世紀になっていました。
21世紀初頭には、人工知能が発達し、宇宙空間でノイローゼになってるはずでした。(1960年代に書かれた有名なSFの中での話です。)
ノイローゼになれるほど、高度な知能ということです。
しかし、現実の世界では、人工知能は実現しませんでした。
せいぜいで、チェスで人間を打ち負かした程度です。(それも、知能ではなく、膨大な計算力=腕力でです。)
その反面、コンピュータの小型化とネットワークの普及は、未来予測を超えていたのではないでしょうか?
今の時代、ネットワーク上に置いてある文書・写真・音楽等をハイパーテキスト(厳密には、ハイパーメディア?)で読む・見る・聴くということは、携帯電話を使って誰でもできます。
「ケータイ」という言葉で通じてしまうこと自体が、社会への浸透ぶりを表わしています。
さらに、ネットワークに繋がっていないハイパーテキストとなると、もうちょっと昔になります。
1990年頃には、HyperCardというソフトウェアによって、Macでは「ハイパーテキスト」が、あたりまえになっていました。
大部分のパソコンユーザは、DOS上のアプリケーションプログラムを使っていた時代です。
さて、21世紀になって、ラダー図はどうなったんでしょうか。
実は、現役の制御用プログラミング言語として、しぶとく生き残っています。
時間とロジックが複雑にからんだFAの分野では、いまだにラダー図は重宝されています。
カムだって、電子式になって生き残っています。
よく「他人が作ったラダー図は読めない」といわれますが、違うと思います。
時間とロジックが複雑にからんだ制御を、ラダー図以外の言語で書こうと思っても「複雑すぎて書けない」というのが本当のところではないでしょうか?
もし、ラダー図以外の言語で書けたとしたら、元々その程度の単純なロジックだから読めるのです。
(ここのところは、異論のある人もいると思います。)
さて、本題に入る前にちょっと、脱線します。
(「すでに、脱線してるだろ!」て、突っ込まないでください。4年半ぶりなもので、書きたいことがいっぱいあります。)
10.1 マルチタスクOS理解への第一歩
話題は変わりますが、私はある時期まで「マルチタスクOS」が全く理解できませんでした。
マルチタスクOSとは「1個のCPUで、小刻みに実行するプログラム(タスク)を切り替えて、外からは複数のプラグラムが走っているように見せるオペレーティングシステム」のことです。
もちろん、私もこの文学的表現のレベルでは「マルチタスクOS」は、十分理解できていました。
わからなかったのは、現実のマイコンの機能で、どうしてプラグラムが複数走る動作ができるかということです。
マイコンの機能を使って、普通に制御プログラムを書くと、メインプログラムに「急ぎでない仕事」をやらせて、「急ぎの仕事」を割込プログラムにやらせることになります。
通常、これで十分です。(というか、OSが関与しない分、より高速な応答ができます。)
もし「急ぎの仕事」より「もっと急ぎの仕事」があるような制御なら、割込処理中にも割込がかかるように許可しておけば「もっと急ぎの仕事」が最優先なります。
これは、多重割込です。
多重割込だと、根拠は無いのですが、ちょっと危ない世界に片足を突っ込んだ気分になり、割込の発生の順番を気にしながら、頭の中で走らせて動作確認していました。
ここまでやると、何とか複数のプログラムがそれぞれの優先順位で走ります。
でも、その優先順位は、固定的でとても「マルチタスクOS」とは、いえません。
同じ優先順位のアプリケーションが複数走ったり、優先順位を動的に変えることができて、初めて「マルチタスクOS」といえるのです。
私もそうでしたが「マルチタスクOS」が理解できてないと、多重割込あたりで、技術的な壁に突き当たってしまうわけです。
さて、この状況は、あるプログラミング上のルールを破ることで、あっさり解決してしまいました。
「マルチタスクOS」が理解できない理由は、無意識のうちに「割込発生によってスタックに積まれたリターンアドレスを、絶対書き換えてはいけない」というルールを設けていたからでした。
マイコンで普通に割込プログラムを書いている範囲では、このルールは、本当に破ってはいけません。
このルールを破ろうものなら、割込からメインプログラムにリターンした瞬間に、CPUは騙されて、書き換えられた「偽りのアドレス」にジャンプして、暴走してしまいます。
でも、この「偽りのアドレス」が、実はOSが意図的に管理している別のプログラムの先頭アドレスだったとしたら、話が違ってきます。
同じ動作でも、今度は暴走ではなく、実行するプログラムが切り替わります。
これが、マルチタスクOS理解への第一歩です。
整理します。
「割込発生によってスタックに積まれたリターンアドレスを、別のタスクのアドレスに書き換えた後で、メインプログラムにリターンすることで、CPUを騙して別のタスクに制御を移す割込処理プログラム」が、マルチタスクOSの核の部分です。
実際には、リターンアドレスだけでなく、演算レジスタやコンディションコードレジスタの値も書き換える必要があるため、これらをRAM上に保存しておいてOSが管理します。
そうしないと、あるタスクが途中で中断された場合、再び同じタスクに戻ったときに、何もしていないのに突然演算レジスタやコンディションコードレジスタの値が変化してしまうことになるからです。
また、あるタスクの実行途中に、別のタスクに切り替わった後、再び元のタスクに戻ったとき「さっき中断した続き」から再開できるかという疑問があるかも知れませんが、これも大丈夫です。
割込発生によって、スタックには実行を中断された場所のアドレスが積まれますので、このアドレスを次回に使います。
なお、割込は外部トリガだけとは限りません。
インターバルタイマによる割込は、必須でしょう。
アプリケーションが、自分から割込をかけてくれと要求することも可能です。
30年位前の6800系のCPUに、すでにSWI(ソフトウェアインタラプタ)という、このための専用命令がありました。
6800系のCPUが、いかに美しい命令体系であったかが、後になってわかりました。
(でも、6800系のCPUで「なぜインデックスレジスタをスタックにプッシュする命令が無かった」のかが、いまだ理解できません。トランジスタが足りなかっただけのことのでしょうか?)
マルチタスクOSではOSが主役だと思います。
CPUは、タスクに時間貸しで割り当てられる資源(労働力)ぐらいの扱いです。
メモリも、タスクに動的に割り当てられる資源の1つです。
私の知るマルチタスクOSは、ここまでです。
正確には、リアルタイムモニタの一部分であるディスパッチャ(タスクを切り替える機能)の部分まででした。
リアルタイムモニタは、ここから先に、メモリ資源の管理とか優先順位の変更とか、タスク間の通信とかの話が出てきます。
正直言って、私には理解できていません。
さて、ここらへんで、4年半前のテーマにもどりましょう。
すでに「1ビットのメモリ」と「アドレスデコーダ」は作りました。
あとは「データセレクタ」を作って、これらを接続しれば、メモリの完成です。
(脱線が長くて、今回は、データセレクタだけで息切れです。)
10.2 データセレクタ
まず、Chap.9を振り返ってみます。
図10.1が、1ビット×4アドレスのメモリのブロック図です。
この図のうち、アドレスデコーダ(黄緑色)と1ビット記憶回路(黄色)は、Chap.8とChap.9で回路は出来上がっています。
残りは、データセレクタ(水色)だけです。
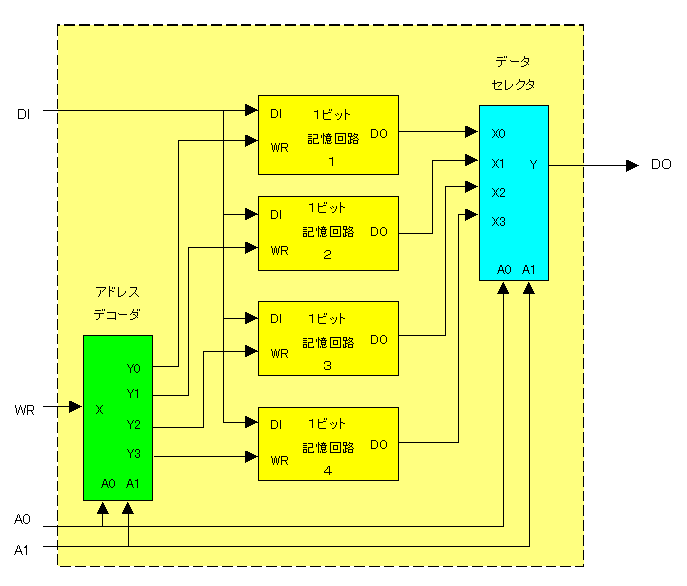 |
このデータセレクタには、X0〜X3の4つの信号が入力されいて、このうちの1つの信号のみがYに出力されます。
X0からX3のうちどの信号をYに出力するかは、表10.1のとおり、A0,A1で決ります。
| A1 | A0 | Y |
| 0 | 0 | X0の値を出力 |
| 0 | 1 | X1の値を出力 |
| 1 | 0 | X2の値を出力 |
| 1 | 1 | X3の値を出力 |
では、表10.1のデータセレクタを、ラダー図の特徴を生かした方法で設計してみます。
X0,X1,X2,X3のどれかの値がYに出力されるわけですが、とりあえず、「X0,X1,X2,X3を、全部Yへ出力しちゃえ!」というのが、図10.2のラダー図です。
もちろん、この回路では、X0,X1,X2,X3の信号が競合していて、正しく動作しません。
大体、選択信号A0,A1がラダー図上のどこにも使われていません。
 |
| 図10.2 データセレクタ(ただし、信号が競合している) |
次に、競合している信号ラインの交通整理をします。
とりあえず作った図10.2のラダー図をじっとみると、どこで信号を切ってやれば競合が無くなるかかわかります。
一目瞭然です。
答えは、図10.3のピンク色の部分でした。
図10.3の4個のピンク色の部分のうち、常に、どれか1つだけしか繋がっていないようすれば、X0〜X3の信号はどれか1つだけしかYへ伝わりません。
 |
| 図10.3 信号の競合を回避するための回路切箇所(ピンク色の部分) |
では、次に、ピンク色の部分に何を挿入してやればよいかを検討します。
1行目のX0であれば、表10.1の「データセレクタの動作」から、「A0=0,A1=0のときのみ繋がる接点」を、挿入してやればよいことがわかります。
ラダー図で書けば、図10.4の通りになります。
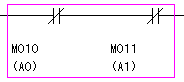 |
| 図10.4 A0=0,A1=0のときのみ繋がる接点 |
同様にして、他の3つのピンク色の部分に入れる接点も簡単にわかります。
これを、挿入した回路が、図10.5です。
これで、出来上がりです。
なんか、拍子抜けしそうなぐらい、あっさり出来上がってしまいました。
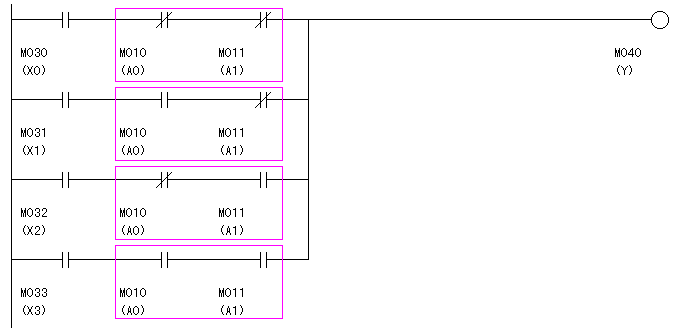 |
| 図10.5 完成したデータセレクタ |
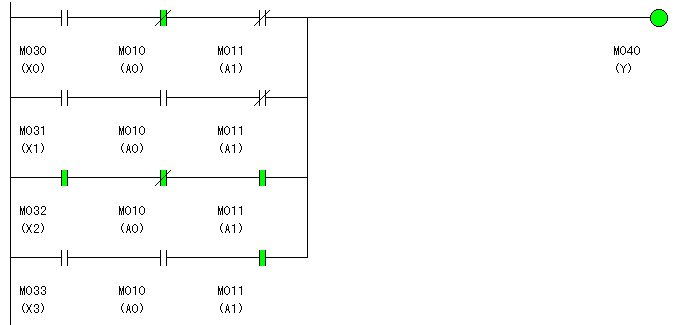
では、例によって、ラダー図開発ツールLD Cv!のシミュレーション機能で動作を確かめてみましょう。
図10.6は、A0=0,A1=1のとき、X2の入力信号(ここでは1)が、Yへ出力されている状態です。
3行目だけに、信号が伝わっている様子が、見ただけでわかります。
これは、すごいことなんです。
 |
次回は、これまで設計してきたアドレスデコーダ、1ビット記憶回路、データセレクタを繋げて、実際に動作させてみましょう。
本当に動くか、楽しみです。